在智能制造領域,機器學習(ML)正成為提升生產效率、優化質量控制、實現預測性維護的關鍵驅動力。從原始數據到可部署的智能模型,這一過程并非一蹴而就,其核心在于構建一個高效、可靠的數據處理和存儲服務流程。本文將深入探討智能制造場景下快速實現機器學習所依賴的核心數據處理與存儲流程。
一、數據采集與匯聚:智能制造的感知基石
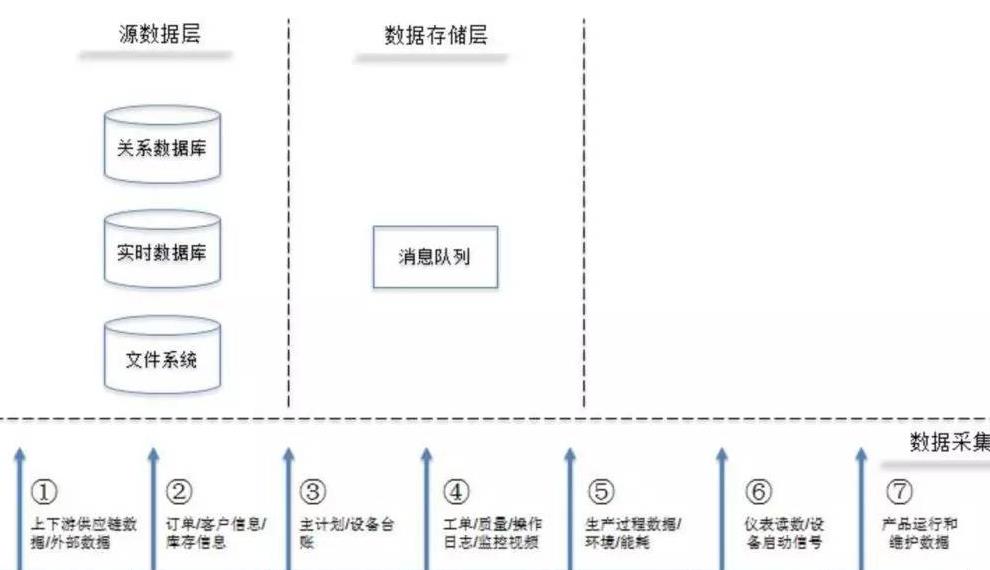
智能制造環境中的數據來源極其廣泛,包括:
- 設備層數據:來自數控機床、機器人、傳感器(如溫度、壓力、振動)的實時運行參數與狀態日志。
- 生產層數據:制造執行系統(MES)中的工單、物料、工藝參數和質量檢測結果。
- 企業層數據:來自ERP系統的訂單、供應鏈及庫存信息。
核心流程:通過工業物聯網(IIoT)網關、邊緣計算設備或直接API接口,將多源、異構的實時流數據與批量歷史數據匯聚到統一的數據接入層。此階段需確保數據的實時性、完整性與初步的時序對齊。
二、數據預處理與特征工程:從原始數據到模型“燃料”
原始工業數據通常含有噪聲、缺失值和不一致問題,直接用于模型訓練效果甚微。
- 數據清洗:處理異常值(如傳感器故障導致的尖峰)、填充缺失值(采用前后插值或基于業務邏輯的填充)、糾正格式錯誤。
- 數據轉換與標準化:將不同量綱和范圍的數據(如轉速與溫度)進行歸一化或標準化,使模型更容易收斂。對于時序數據,常需進行重采樣以統一頻率。
- 特征工程:這是提升模型性能的關鍵。在智能制造中,特征常從時序數據中提取,例如:
- 統計特征:均值、方差、峰值、峭度。
- 時域/頻域特征:通過傅里葉變換提取頻譜特征,用于振動分析。
- 領域特征:基于工藝知識的特定組合指標(如設備綜合效率OEE的構成因子)。
三、數據存儲與管理:構建可靠的數據湖/倉
為支持機器學習不同階段(探索、訓練、推理)的需求,需要分層、彈性的存儲架構。
- 原始數據存儲區(數據湖):使用如Hadoop HDFS、云對象存儲(如AWS S3, Azure Blob)低成本存儲匯聚而來的原始數據,保留最大粒度信息以備后續深度挖掘。
- 處理與特征存儲區:存儲清洗后、標注好的數據集以及生成的特征表。采用列式存儲(如Apache Parquet)或特征存儲數據庫,便于高效查詢和批量讀取,供模型訓練使用。
- 元數據與版本管理:記錄數據來源、處理流水線、特征定義及數據集版本,確保實驗的可復現性。工具如MLflow、DVC在此環節至關重要。
- 實時數據管道:對于需要在線學習或實時預測的場景,需構建基于Kafka、Pulsar等流處理平臺的數據管道,將處理后的特征低延遲地輸送給在線模型服務。
四、核心支撐服務:實現流程自動化與加速
要“快速”實現機器學習,必須將以上流程服務化、自動化。
- 可復用的數據處理流水線:使用Apache Airflow、Kubeflow Pipelines等工具將數據采集、清洗、特征提取等步驟編排成自動化工作流,確保數據的一致性和生產化。
- 特征平臺:構建中心化的特征存儲和計算服務,實現特征的定義一次、多處復用,避免訓練與推理服務的特征不一致問題。
- 數據質量監控:持續監控數據流的完整性、新鮮度和統計分布。一旦發現數據漂移(如傳感器精度下降導致的數據分布變化),能及時告警,因為數據漂移是導致模型性能衰減的主要原因之一。
五、與模型生命周期的閉環集成
數據處理與存儲并非孤立環節,它與模型開發、部署、監控緊密相連。
- 訓練階段:從特征存儲中快速抽取一致、版本化的訓練數據集。
- 部署與推理階段:在線服務從特征管道或特征庫中實時獲取預處理后的特征,進行預測。
- 監控與迭代階段:持續收集模型預測結果與實際反饋(如預測性維護是否準確),并將這些新數據回流至數據湖,形成“數據->模型->應用->新數據”的增強閉環,驅動模型持續優化。
結論
在智能制造中,機器學習價值的快速兌現,高度依賴于一個堅實、敏捷的數據處理與存儲服務基礎架構。這一核心流程將混亂的原始工業數據轉化為高質量、可追溯、易獲取的“模型就緒”數據,并確保其在生產環境中持續、可靠地流動。企業只有系統化地構建并優化這一數據基石,才能讓機器學習真正融入智能制造的血液,實現從“制造”到“智造”的跨越。